
Machine Learning is a method of teaching a computer how to accomplish a task without explicitly programming it to do so. Instead, data is fed into an algorithm that improves outcomes over time. Similar to how organic life learns.
The term was coined in 1959 by Arthur Samuel at IBM, who was developing artificial intelligence that could play checkers. Half a century later, predictive models are embedded in many of the products we use every day which perform two fundamental jobs. One is to classify data like - is there another car on the road? or, Does this patient have cancer? The other is to make predictions about future outcomes like - will the stock go up? or, Which blog do you want to read next?
Acquire, clean and separate data
The first phase in the process is to collect and clean data, and there are lots and lots of data. The better the data represents the problem, the better the results ("Garbage in = garbage out"). The data needs to have some kind of signal to be valuable to the algorithm for making predictions. And data scientists perform a job called feature engineering to transform raw data into features that better represent the underlying problem.


The next step is to separate the data into a training set and testing set. The training data is fed into an algorithm to build a model. Then the testing data is used to validate the accuracy or error of the model.
Types of algorithm and error function

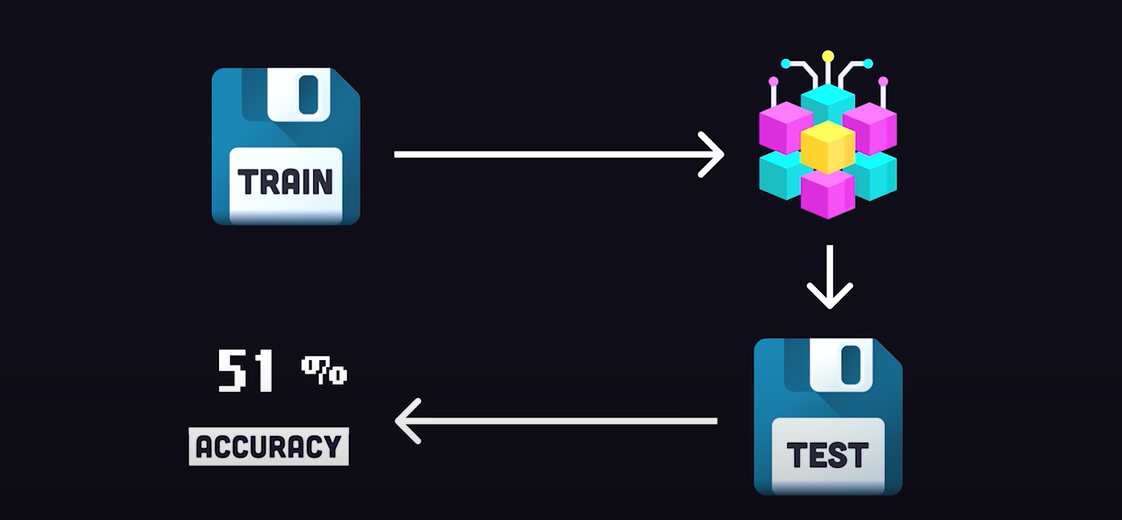
The next step is to choose an algorithm, which might be a simple statistical model like linear or logistic regression or a decision tree that assigns different weights to features in the data. You may even use a Convolutional Neural Network, which is an algorithm that not only assigns weights to features but also generates new features automatically from the input data. And that's extremely useful for data sets that contain things like images or natural language, where manual feature engineering is virtually impossible. Every one of these algorithms learns to get better by comparing its predictions to an error function. If it's a classification problem like - is this animal a cat or a dog? the error function might be 'accuracy'. If it's a regression problem like - how much will a loaf of bread cost next year? then it might be a 'mean absolute' error.
Languages used in Machine learning


Python is the language of choice among data scientists, but R and Julia are also popular options. And there are many supporting frameworks out there to make the process approachable.
End Result


The result of the machine learning process is a model, which is just a file that takes some input data in the same shape that it was trained on, then spits out a prediction that tries to minimize the error that it was optimized for. It can then be embedded on an actual device or deployed to the cloud to build a real-world product.
This has been machine learning in 1 minute. Subscribe if you want to see more short blogs and other machine learning content on this blog. Thanks for watching and I will see you at the next one.
